

《系统日知录》会持续更新数据库、分布式系统、存储、ML System 相关的想法、翻译、笔记和文章,通过深入浅出的持续解析,帮助业务开发程序员建立底层知识体系。 写代码不是全部,系统是综合学问。 不谋全局者,不足谋一域; 不学系统者,不足学编程。 专栏是买断制,在保证每篇文章的知识密度的基础上,持续不定期更新。会随缘将一些文章分享到公众号:“木鸟杂记”。关注该公众号后回复:“优惠券”,可以领取本专栏八折优惠券。 关于专栏内容,想交流可以留言、也可加我微信 qtmuniao。有个交流群,如果想加群可备注。
一文科普 19 个核心 AI 术语(上)
本文编译自一个非盈利组织的科普杂志平台:quantamagazine,虽然是非盈利的,但是背后有量化大金主,里面的文章质量还挺高的,感兴趣的同学可以去看看。
文章术语来自:What the Most Essential Terms in AI Really Mean,结合我转到 AI 行业后一些时间,用更接地气的语言对原文“编译”和扩充了一遍。即使你不做大模型,但是在 AI 如此日新月异的发展速度下,对一些 AI “行话”的理解,有助于建立一些基本认知,以听懂一些常见的 AI 讨论。本文遴选除了 19 个高频被提及的概念,分享给你。由于篇幅略长,本篇是上。
1. 人工智能(Artificial Intelligence)
根据约翰·麦卡锡(John McCarthy)1955 年的定义,人工智能是“制造智能机器的科学与工程”。几十年来,人工智能的理念和实践与认知科学、机器学习、机器人学和语言学等多个领域交叉融合。如今,AI 主要指使用人工神经网络的系统,尤其是基于生成模型(如 ChatGPT,Claude)的应用,通常被直接称为 AI。
AI 的浪潮基本上是每十来年就有一阵复兴。这一轮我们都知道,是以 “生成式大语言模型”(LLM)技术为代表。与“生成”对应的是“理解”,但毫无疑问,现在的大模型也有非常卓越的理解能力,才能生成。这里叫生成式 AI 可能和其主要利用了 Transformer 中 Decoder-Only 的架构有关系。
上一轮 AI 浪潮大家应该也有印象,以“深度卷积神经网络”为基本技术,通过批量归一化、残差连接、Dropout 等技术让训练深层网络成为可能(以前会有梯度消失和梯度爆炸问题,得需要精密的微调数据分布和模型结构)。最有代表性的应用领域是计算机视觉,比如大家现在熟知的技术“人脸识别”。
所以 AI 是一项很泛的概念,日常大家也用的很模糊,当下的语境里,AI 基本等于大语言模型。
2. 生成式 AI (Generative AI)
上面提了一嘴,AI 主要有两种类型的任务——理解和生成。
大模型在文本模态上通常同时具有理解和生成能力。但在图片模态上,这两者分的更开一些,因此举例可能更好理解。如果大模型可以做我们拍照给他的课后题,我们就说该大模型有图片模态的理解能力;但该模型同时并不一定能按你的指令生成新的图片。
当然,这也是因为,当前基础语言模型通常使用 Transformer(自回归)架构,而图片生成模型通常使用 Diffusion 架构,还没有融合到一块。当然,最近谷歌发布的 Gemini Diffusion 已经开始将 Diffusion 模型应用于文本生成。
3. 基准测试(Benchmark)
用于评估 AI 系统能力的一组特定任务,一个基准测试主要由数据集+评测方法构成。好的基准测试是推动 AI 快速进展的重要力量,有大量论文都是围绕基准测试发表的,引用量也相当大。
2012 年,ImageNet 基准测试确立了神经网络的主导地位;2018 年,GLUE 基准测试对基于 Transformer 的语言模型也起到了类似作用。
设计一个好基准测试时需要格外谨慎,在对应领域中数据集分布要合理、评测方法要科学。例如,BERT 曾利用“not”一词常出现在正确答案中的规律,在某个推理基准测试中取得高分;但移除这一偏差后,BERT 的表现降至随机水平。
前阵有篇圈内很有名的文章“(AI的)下半场”,出自 OpenAI 一个华人研究员:姚顺雨。大体意思是说,在 AI 发展的上半场,正是一个个 Benchmark 不断推动了展示和验证新训练方法和模型的改进。但在下半场,AI 要转到更关注真实世界的应用价值,而非高度抽象出的侧面—— benchmark。
4. 偏差(Bias)
AI 输出结果不符合人类认知或价值观。比如训练于大型互联网数据集的生成模型常含有负面偏见:2023 年时,图片生成模型 Stable Diffusion 倾向于将“CEO”生成为较浅肤色的男性。
模型有偏,通常是因为数据有偏,这主要涉及喂给大模型的数据分布的问题,因为大模型本质上就是在拟合你给它的数据的概率分布,再按照这个概率分布进行采样生成。
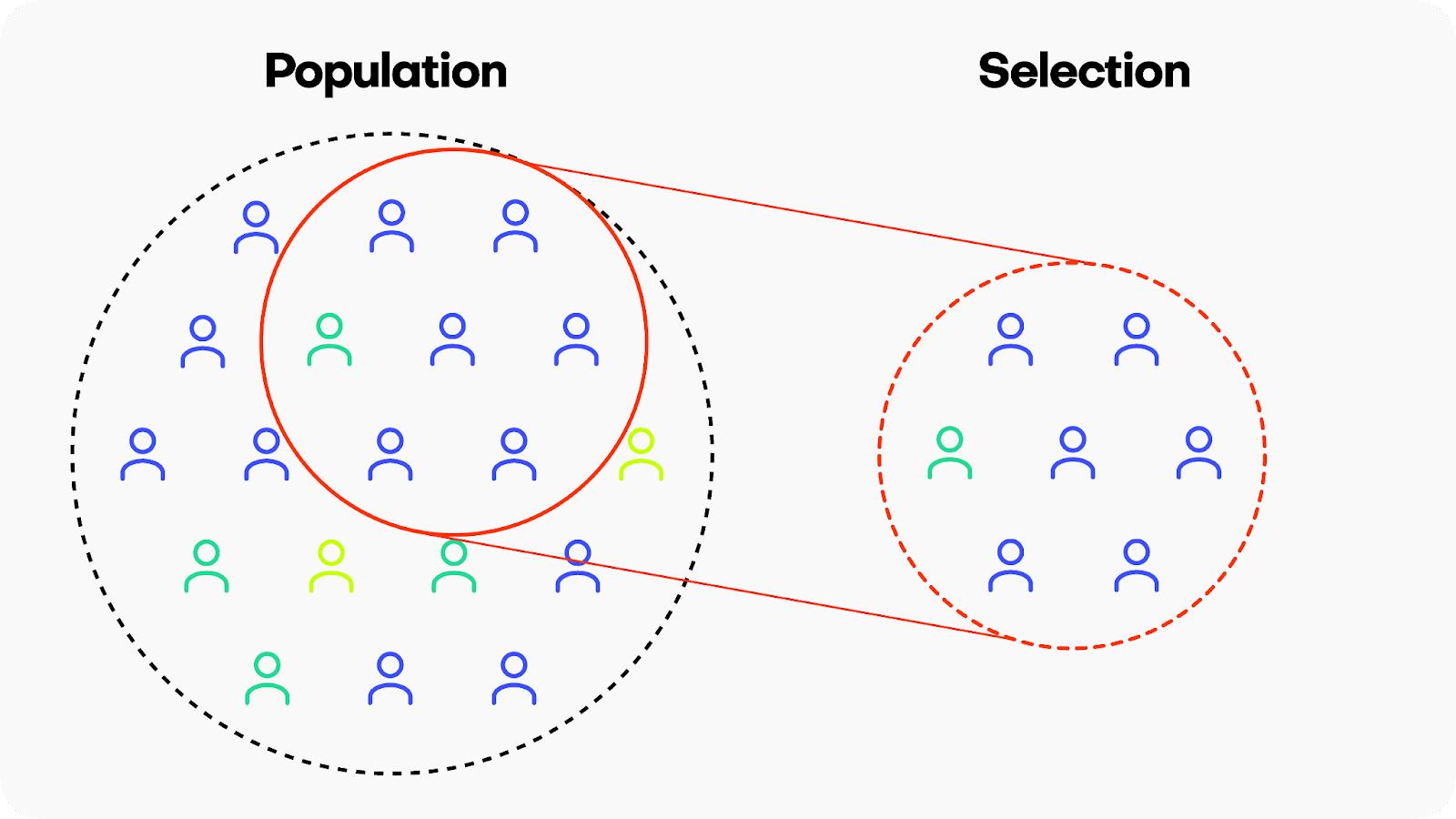
当然,造成数据有偏的原因有很多:
人类的价值观本来就是多样的。很难用同一个大模型去满足不同国别、族别人的需求。
互联网数据并不符合物理世界信息分布。比如互联网上英文数据贼多、有偏见的信息可能会更大范围的传播。
预训练阶段在遴选数据时方法有问题。比如过滤策略有问题导致某些种族偏见或者成人信息没有过滤干净,比如聚类方法有问题导致数据分布中某一个类别的数据格外多。
当然,还有很多其他原因,但从逻辑链条来推导数据来源时,大致可以按以上类别分。我们有时候会说,本质上模型是用数据进行编程。其实是指,我们在训练模型时需要精确控制送进模型中的数据覆盖度和分布。
当然,我们也可以通过后训练( alignment 和 RL)来对模型进行纠偏。
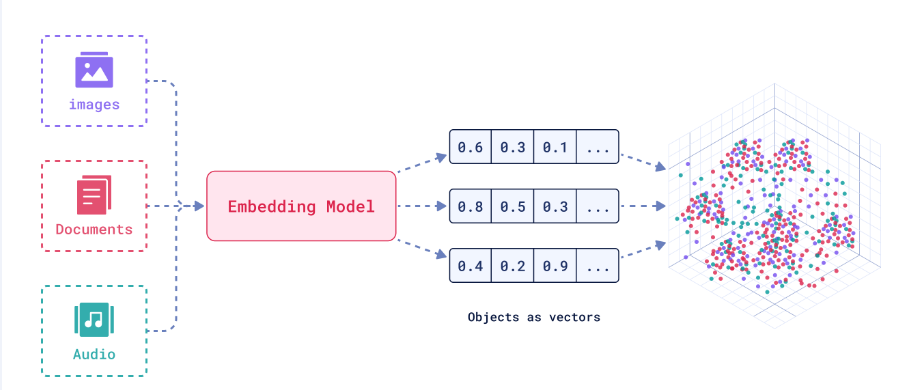
5. 嵌入(Embeddings)
高维数据(比如一张图片、一个文档)在低维空间中的归一化表征(比如一个向量)。
这么说可能有点抽象,举个例子,假设我们有 1w 张图片,可以为每个图片使用某种方法抽出一个 768 维度浮点型向量。如果该向量抽的好,能包含原图片所有信息。则可以很方便用这些 embedding 加很薄几层 MLP(多层感知机,可以理解为很薄的神经网络),训练出各种分类模型,比如判断是不是截屏、判断是不是游戏解说、判断是不是地貌风景;也可以利用这些 embedding 对原图片或者文档进行聚类。
可以从例子看出,这就是传统机器学习中常见的降维(从高维图像空间到低维向量空间)的一种方法,只不过现在有了大模型后,其对 embedding 抽取能力要比传统机器学习方法(比如 PCA,主成分分析)强太多,这就是所谓的大模型压缩能力更强嘛。
此外,还可以将不同模态映射到同一个向量空间,从而让其可比,这样就能通过文字检索图片。
6. 模型 (Model)
每个模型有其自己独特的神经网络结构、有其特定的训练数据集和特定的训练方法。这三者结合,决定了每家公司产出的模型的能力范围。
概括来说,模型使用神经网络作为基本构造法,然后利用互联网上的海量数据来对神经网络中的参数进行训练迭代。最后产出的模型可用于推理,进行预测。具体当前最常见的聊天形式,就是会以对话的方式,以语言为载体响应所有用户的输入。
7. 基础模型(Foundation Model)
斯坦福大学研究人员在 2021 年创造的一个短语,用于描述具有通用能力的模型基座。比如用于图片生成的 DALL-E 和用于文本生成的 GPT-3 。
这些模型在预训练时见过的数据足够多,因此稍加微调(复杂一点需要微调来改变模型参数、简单一点只要尝试合适的提示词就行;前者称为 finetune,后者称为 few-shot)就能适应相当广泛的任务。而不像传统机器学习中的小模型那样,由于见的数据太少,只能满足特定领域的任务(如人脸识别),也没有什么后期微调的可能。
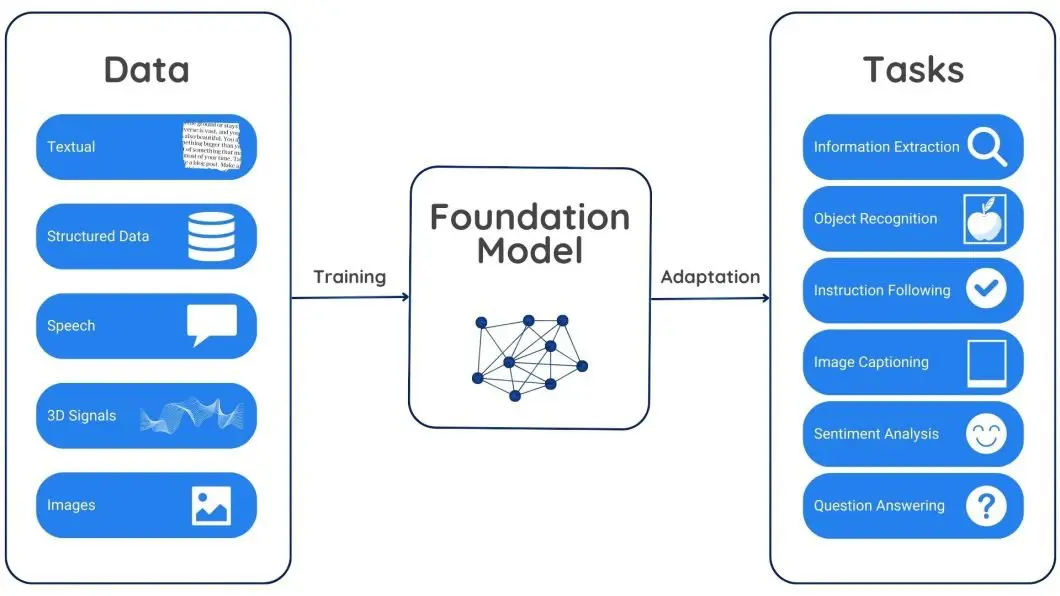
当前,由于微调方向不同,每家模型可能都有自己的特色。比如 Deepseek V3 号称(benchmark上)在数学和编码方面比较强;Claude 在复杂代码能力上(真能干活)上比较强;ChatGPT 总体比较均衡等等。
最近各家大模型公司,在研究通过加入物理学、医学、生物学等专业数据,来对模型进行微调以获得垂直领域能力更强的专家模型。比如听说谷歌的 AlphaFold 能够帮助发现新的蛋白质结构。
9. 泛化(Generalization)
模型的泛化能力的核心是指模型在训练完成后,应用于它从未见过的、新的数据时表现如何的能力。更严谨地说,泛化能力衡量的是一个在特定训练数据集上训练的模型,对于来自同一数据分布但未在训练中出现过的数据(即测试数据集或真实世界数据)进行准确预测或判断的能力。
为什么基础模型有被进行 finetune 的可能性,就是因为其泛化能力。而传统的小模型,通常由于过拟合,导致泛化能力相对较差。比如,我们在利用传统卷积神经网络训练了一个猫脸识别的小模型是,只给它喂猫的正脸数据;该模型在面对猫的侧脸或者倒脸时,就不一定能识别出来。

10. 幻觉(Hallucination)
你问大模型问题时,他可能会一本正经的胡说八道:编造一些听起来合理但事实上错误或者虚构的输出。幻觉并不一个内涵精确的术语,更像是对上述现象直觉的描述。
例如,大模型可能会捏造一些不存在的历史;也可能会生成具有六个手指的人。

通过后训练(比如强化学习)可以缓解幻觉,但目前没有一种办法能完全消除幻觉——因为模型本质上是基于学到的概率分布来按采样生成下一个 Token。这决定了它肯定是有概率出错的。
使用 ray.data 进行大规模数据处理(三):优化规则
ray.data 是基于 ray core 的一层封装。依赖 ray.data,用户用简单的代码,就可以实现数据大规模的异构处理(主要指同时使用 CPU 和 GPU)。一句话......
infra 面试之数据结构九:并行迭代
前面的面试题基本都是一堆 C++,毕竟传统 Infra 开发讲求高性能,一般都用 C++ 和 Rust。但随着 AI 相关的 Infra 兴起,Python 的地位也越来越重要。正好,最近写 P......
【每天学点数据库】Lecture #15:并发控制
内容主要来自 CMU 15445 Fall 2022 的课程讲义和授课视频,结合笔者的一些内核开发实践,形成一系列相对独立、但又相对勾连的小文。如果你对数据库内核开发感兴趣,......
在云上进行大规模数据处理的一些实践
随着云基础设施的不断成熟,新兴的公司为了快速实现业务目标,一般都会让基础设施上云。而在云上进行开发与传统上直接使用物理机开发其实有很大不同。云上更强调共享和弹性,此外,规模变大又会带来隔离性。这......
t-SNE :一种“降维不扰邻”的有趣算法
考虑这样一个场景,你有一大堆千奇百怪的图片,想将其分门别类,并能够在分类好之后证明你分的类确实不错。
当数据量很小时(比如几百个),你可以定个分类的标准,然后找些人来按照标准分一......
深度学习入门小话 —— 卷积的由来
从上学时开始就多次尝试入门深度学习,但总徘徊门外而不得入。近来有一些工作上的体感,加之李沐老师的这门好课,终于对以前困惑的点有所感悟。
因此,本系列定位是 b 站上李沐老师主讲的《动......
数据可视化利器—— streamlit 的有趣哲学
streamlit 是一款可以快速进行简单网页开发的 Python 库,其 slogan 是:
A faster way to build and share data apps
【每天学点数据库】Lecture #14:代价估计
内容主要来自 CMU 15445 Fall 2022 的课程讲义和授课视频,结合笔者的一些内核开发实践,形成一系列相对独立、但又相对勾连的小文。如果你对数据库内核开发感兴趣,欢迎关注。
<......Memgraph 系列(三):高效扫描和垃圾回收
Memgraph 是一个内存型图数据库,使用 OpenCypher 作为查询语言,主打小数据量、低延迟的图场景。由于 Memgraph 是开源的(repo 在这,使用 C++ 实现)我们可以一窥......